MapReduce论文笔记
背景
在学MIT 6.824的时候,它的第一个Lab要求实现一个单机并发版本的MapReduce,所以这篇文章主要记录关于MapReduce和实验对应的内容。
Programming Model
这里主要介绍了MapReduce的编程模型,它会接收一组键值对作为输入任务,同时输出一对键值对作为结果。它提供了两个函数给用户使用, 需要注意的是Map和Reduce都需要用户自己来实现:
- Map: 接收一对键值对,如何生成相关一组值。将所有相同中间键的中间值组合在一起,之后传输给Reduce函数。
- Reduce: 接受一个中间键和与该键相关的一组值, 将这些值合并在一起,形成一个可能更小的值集合。通常,每次调用Reduce函数只会生成零个或一个输出值。中间值通过一个迭代器(iterator)传递给用户的Reduce函数。这允许我们处理那些太大以至于无法在内存中存储的值列表。
具体来说,Map函数负责将输入数据映射为中间键/值对,这些中间键/值对将按照键的相同性被分组,然后传递给Reduce函数。Reduce函数则负责处理这些分组后的中间值,将它们合并在一起,生成最终的输出键/值对。
这种分离的处理方式允许MapReduce框架高效地处理大规模数据,并且让用户专注于编写特定的处理逻辑,而不需要担心底层的数据分发和整合。
经典的例子-单词统计(world count)
Map函数:
- 输入:一个文档的名称(key)和该文档的内容(value)。
- 处理:Map函数遍历文档的内容,将文档内容分割成单词。对于每个单词,Map函数发出中间键/值对,其中键是单词(word),值是固定的字符串“1”(表示该单词出现了一次)。
- 输出:多个中间键/值对,例如(”apple”, “1”),(”orange”, “1”),等等。
Reduce函数:
- 输入:一个单词(key)和该单词的计数列表(values)。
- 处理:Reduce函数迭代计数列表,将所有计数相加,得到该单词的总出现次数。
- 输出:一个键/值对,其中键是单词,值是该单词的总出现次数,转换为字符串形式。
更多例子
分布式Grep(分布式文本搜索)
统计URL访问频率
反向Web链接图
每个主机的词项向量(文本摘要)
MapReduce工作流程
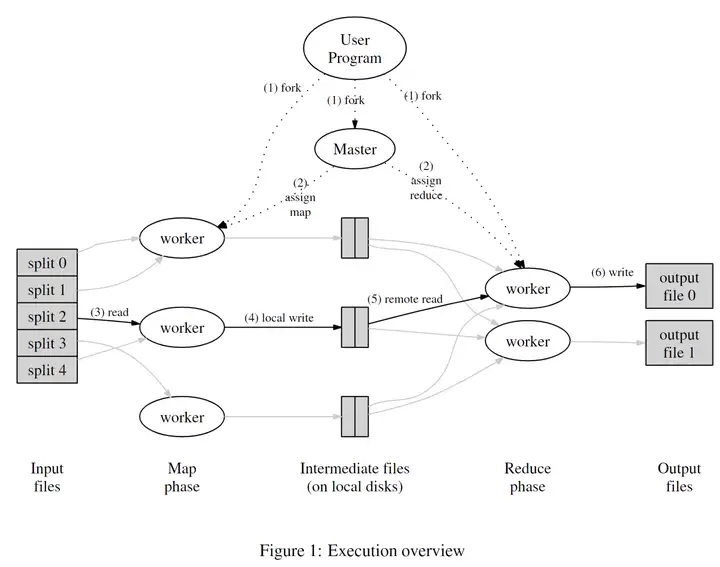
用户程序中的MapReduce库会先将输入文件切分为M个片段,通常每个片段在16MB到64MB之间,具体大小可以让用户通过参数进行指定。之后创建多个程序副本。
副本角色分为两种: master和worker,集群中只有一个master副本,剩下都是worker副本。master会对worker进行任务分配,这里有M个Map任务以及R个Reduce任务要进行分配。master会给每个空闲的worker分配一个map任务或者一个reduce任务。
被分配到map任务的worker会读取相关输入数据片段,之后会从数据数据中解析出键值对,并将它们传入到用户自定义Map函数中。Map函数所生成的中间键值对会被缓存在内存中。
每隔一段时间,被缓存的键值对会被写入到本地硬盘,并通过分区函数分到R个区域内。这些被缓存的键值对在本地磁盘的位置会被传回master。master负责将这些位置转发给执行reduce操作的worker。
当master将这些位置告诉了某个执行reduce的worker,该worker就会使用RPC的方式去从保存了这些缓存数据的map worker的本地磁盘中读取数据。当一个reduce worker读取完了所有的中间数据后,它就会根据中间键进行排序,这样使得具有相同键值的数据可以聚合在一起。之所以需要排序是因为通常许多不同的key会映射到同一个reduce任务中。如果中间数据的数量太过庞大而无法放在内存中,那就需要使用外部排序。
reduce worker会对排序后的中间数据进行遍历。然后,对于遇到的每个唯一的中间键,reduce worker会将该key和对应的中间value的集合传入用户所提供的Reduce函数中。Reduce函数生成的输出会被追加到这个reduce分区的输出文件中。
当所有的map任务和reduce任务完成后,master会唤醒用户程序。此时,用户程序会结束对MapReduce的调用。